Multi-stage Aggregated Transformer Network for Temporal Language Localization in Videos
Task : 자연어 문장을 통해 비디오에서 특정 순간에 대한 구간 검색
이전 방법 문제점
1) 비디오와 언어 쿼리를 활용하는데 있어서 시각-언어의 alignment 을 어떻게 효과적으로 모델링 할 것인가?
2) 비디오에서 특정 순간을 어떻게 정확하게 구간화 할 것인가?
문제해결하기 위한 방법
새로운 이미지-언어 트랜스포머 백본 모델 고안
- 시각 및 언어 시퀀스의 모든 요소를 반복 및 정렬을 가능하게 함
- 양쪽 구조를 통일하고 모달리티를 유지
- 백본에 사용되는 multi-stage aggregation 모듈 제안 (시작, 중간 및 종료 단계에 해당하는 단계별 표현 계산 후,
concat하여 최종 순간 표현 형성)
1. 소개
시간에 따른 구간화는 비디오 분석에 주요하고 근본적인 태스크입니다.
기존에는 시간에 따른 행동별 구간화가 연구되었고 최근에는 자연어를 통해 시간별 구간화가 연구되고 있으며,
비디오 검색, 비디오 캡셔닝, 인간-컴퓨터 상호작용등에 활용될 수 있습니다.
기존방법
1) 비디오와 언어 쿼리를 활용하는데 있어서 시각-언어의 정렬을 어떻게 효과적으로 모델링 할 것인가?
- 비디오 및 언어 시퀀스를 별도로 처리한다음 융합함
=> 쿼리 문장을 단일 벡터로 인코딩하면 필연적으로 일부 세부 의미 손실 및 상호 작용 및 alignment 달성 하기 힘듬
=> 비디오 시퀀스의 시간적 관계는 충분한 컨텍스트 정보를 얻기에 충분하지 않은 로컬 작업에 의해 모델링됩니다.
2) 비디오에서 특정 순간을 어떻게 정확하게 구간화 할 것인가?
- full convolution, pooling 또는 ROI pooling을 사용하여 후보 구간에 대한 Featrue 추출
=> 이러한 Representation은 충분히 식별적이지 않음, 구간이나 사건은 시작, 중간 끝의 단계를 갖고 있으며, 이러한 단 계들의 정보가 정확한 구간화를 위해 중요함
=> 평균 풀링은 단계별 정보를 버리며, 다양한 단계를 정확히 매칭할 수 없음
=> 컨볼루션이나 RoI 풀링 방법들이 다양한 단계를 어느정도 모델링 할 수 있지만 명시적인 단계-특정 표현에 의존하지 않으며 구간화를 위한 핵심 요소를 포착하기 어렵다.
=> 컨볼루션은 고정된 커널 구조를 갖고 있기에 다양하며 동적인 구간들에 적용하기 어려움
제안방법
- the visual-language transformer backbone
- the multi-stage aggregation module topped on the transformer backbone.
=> 기존 Bert에 영감을 받았으나, Bert는 시각과 언어 시퀀스를 통일된 시퀀스로 처리하여 서로 다른 양식의 두 시퀀스를 간결하고 효율적인 방식으로 처리하나, 다른 양식들은 양식만의 특정한 내용 및 관계 패턴을 갖고 있을 수 있으므로 이러한 방식으로 처리하는 것이 최적은 아님.
=> 트랜스포머 백본에서 단일 Bert 구조는 유지하지만, Bert 파라미터를 서로 다른 그룹으로 분리하여 각각 시각 및 언어 컨텐츠 처리함. 간결함과 효율성은 유지하면서 두가지 양식을 보다 효과적으로 모델링
=> 정확한 구간화를 위해 the multi-stage aggregation module를 제안하였고, 비디오 시퀀스의 각 요소에서 3개의 다른 시간 단계 즉, 시작, 중간, 종료 단계 해당하는 3개의 단계별 Representation 계산함
=> 후보 구간을 얻기 위해, 시작, 중간, 끝의 Representation을 Concat하여 최종 구간 Representation 생성
=> 제안된 네트워크의 구조는 간단하고 효율적이며 우수한 시간-구간화 성능을 낼뿐만 아니라 매우 빠른 속도임
공헌사항
1) 언어를 통한 구간화를 위한 새로운 시각-언어 트랜스포머 백본 모델 제안
- Bert구조를 유지하면서, 파라미터 그룹을 나누어 양식간 컨텐츠를 개별적으로 처리
2) the multi-stage aggregation module 제안하여 보다 정확한 언어를 통한 구간화 달성
3) ActivityNet Captions and TACoS 데이터셋에 대해 광범위한 실험 수행하여 모델이 효과적임을 입증함
모델
- Feature
비디오 시퀀스 = X = {x1, x2,· · · , xT},
각 비디오는 {S, ts, te} 구간-문장 페어 쌍으로 주석이 달림
=> S: 자연어 문장, ts : start time, te : end time
시각적 피쳐 : 원본 영상을 균등하게 N video 클립으로 나눈후, 각 클릭을 CNN 모델을 통해 피쳐추출
평균풀링을 활용해, 클립에 대한 최종 피쳐 얻음

자연어 피쳐 : Glove Embedding

- The Visual-language Transformer Backbone


l+1-th forward process :

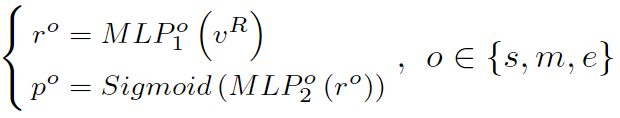
vR : the output visual representation from the transformer backbone
rs, rm, re : the representations for starting, middle and ending stages respectively
ps, pm, pe : prediction scores if the element is the starting, middle and ending stages respectively
Define the ground truth of starting, middle and ending scores, For each moment-sentence pair {S, ts, te}

gs, gm, ge : the ground truth of starting, middle and ending scores
i : the position index in the video sequence
σo = αo(te − ts), o ∈ {s, m} is the standard deviation of the unnormalized 2D Gaussian distribution
αo : a positive scalar to control the value of the standard deviation
